Talend est une suite logicielle ETL, dont l'une des briques existe sous licence libre et gratuite : Talend Open Studio for Data Integration (TOS), dédiée à l'intégration et à la manipulation de sources de données hétérogènes.
Téléchargez l'outil depuis la page officielle et installez-le sur votre machine. Il s'agit de dézipper le fichier fourni et de le placer près de vos programmes. Il contient deux exécutables (.exe), selon la binarité de votre machine, dont vous pouvez créer un raccourci.
N'hésitez pas à tester les deux exécutables en 32 ou 64 bits si besoin (incohérences constatées sur certaines machines sous Windows, mais sans problème fonctionnel).")
Pour fonctionner, Talend a besoin d'une version récente de Java.
Ce tutoriel d'initiation suppose que soyez déjà familier avec les SGBD MySQL et/ou Postgres, et que vous en disposiez.
Les images de cet article sont cliquables et affichent des informations contextuelles supplémentaires.
Introduction
Quelques définitions
Quelques définitions et/ou points de vue personnels selon mes usages. Rien d'exhaustif bien sûr.
Entrepôt de données (data warehouse)
Un entrepôt de données manipule de la data en vue de la traiter en dehors des systèmes de production qu'il agrège. Il s'appuie lui-même sur une base de données, mais séparée des vraies bases.
Un entrepôt n'est pas une sauvegarde (même s'il peut être utilisé en tant que telle), ni une archive (même s'il peut être à l'œuvre dans un système d'archivage).
Le fonctionnement en entrepôt correspond davantage à une démarche plutôt qu'à un outil. L'entrepôt ne peut pas être défini par l'usage de tels ou tels SGBD ou ETL. Les process préalables apparaissant parfois progressivement et naturellement dans les systèmes (au gré des besoins récurrents). Un entrepôt de donnée est finalement une méthode, souvent mise en place pour répondre à un besoin récurrent de traitement de données sans toucher aux données originales.
Dans la pratique, un entrepôt sera une autre base de données, stockée classiquement avec votre SGBD préféré, mais rarement avec des finalités de production (du moins pas pour les utilisateurs lambdas des systèmes agrégés. Du moins... mieux vaut ne pas rentrer dans le détail pour appréhender les entrepôts de données, c'est inutile pour commencer. Mais gardez en tête que dans la pratique, les entrepôts font parfois effectivement communiquer des bases étant toutes en production. En cas de big data par exemple, ou de systèmes de stockage de données trop différents, ou provenant d'outils trop différents, bref...).
La grande finalité de la méthode est sans doute de permettre l'amélioration de l'intégrité d'usage des données (statistiques, exports, exploitations tiers...) sans peser sur les systèmes en production (avec des requêtes trop lourdes...) ni corrompre l'intégrité système (la structure des tables...) ou l'intégrité client (les données saisies).
ETL (Extract Transform Load)
Les logiciels ETL vont extraire, transformer puis charger des données. Ils sont très bien adaptés aux sources de données diverses que peuvent produire les outils informatiques. Un ETL ne contient pas de données en soi, mais plutôt des connexions aux sources de données, et du code de traitement.
Les ETL sont capables de gérer des entrepôts, mais ne sont pas indispensables à cette fin. Ils nous facilitent toutefois grandement le travail, contribuent à standardiser et à centraliser les process.
Il existe des ETL spatiaux (FME par exemple), ou encore un composant spatial pour Talend, et dont on imagine les multiples applications : agrégation de données spatiales issues de sources diverses, comparaison d'entités spatiales à la voléee, génération de petits fichiers pour des applications en fin de chaîne... Cela avant insertion en BDD ou dépôt en FTP via les fonctionnalités classiques de l'ETL.
Métadonnée
Dans Talend, une métadonnée est un accès à une source de données (BDD Mysql, Oracle, Postgres, accès FTP, fichier local, distant...). L'équivalent des Connecteurs ou Readers sur d'autres ETL.
Cet usage du terme métadonnée dans Talend s'explique facilement : on décrit la source de données au logiciel (type, host, login, password, schémas utilisés...), ce qui permet au logiciel de l'utiliser en tant que source de données.
Job
Dans Talend, un job est typiquement un process d'extraction -> transformation -> dépôt de données (une tâche).
Vous le créez, le paramétrez puis une fois mis en place il est exécutable via un simple bouton. Un job peut exécuter de nombreuses opérations à la suite.
Schéma
Dans Talend, un schéma est la définition d'un seul objet de bases de données (une table ou une vue en général). À la création d'une métadonnée, des schémas sont pré-générés, mais doivent être contrôlés.
Quand la structure des tables impliquées dans un job est modifiée dans les bases de production, les schémas doivent souvent être re-générés/contrôlés dans Talend. Souvent le logiciel le détectera dès l'ouverture, et vous proposera de le faire en cascade (partout où les schémas impliqués sont utilisés par vos jobs).
Datamart
Un sous-ensemble d'un entrepôt de données. Personnalisé pour correspondre à un usage particulier par exemple.
Datalake
Un sur-ensemble d'entrepôts de données. Dans certains contextes collaboratifs ou partagés par exemple.
Quelques exemples d'utilisation
- Déplacer régulièrement des données issues de sources hétérogènes. Des fichiers Excel, CSV, shapes...
- Agréger régulièrement des sources de données hétérogènes dans un entrepôt.
- Créer régulièrement et à la volée de petits fichiers, destinés à des applications tiers.
- Alimenter régulièrement une grosse base, liée à une/des application(s) tiers.
- ...
Notez la récurrence du mot régulièrement. En effet quand un tel besoin est ponctuel, un ETL n'est pas forcément le moyen le plus simple d'arriver à ses fins.
Bien souvent quand l'un de ces besoins se manifeste, il ira de pair avec de besoins de transformation des données. Exemples :
- Dédoublonner des données issues de sources hétérogènes, à des fins statistiques ou d'exploitations tiers...
- Concaténer des champs, segmenter des champs, agréger des tables... à des fins d'exploitations tiers.
- ...
Connexion à des bases de données SQL distantes

Importez le fichier customer dans une base de données MYSQL nommée ma_base_1 et le fichier warehouse_customer dans une base de données Postgres nommée ma_base_2.
Astuce
Pour Postgres, supprimez des fichiers .sql les lignes des définitions (avant le CREATE TABLE...) et les guillemets obliques. Vous devrez aussi retirer la mention du moteur des tables (ici MyISAM), et modifier les types int en integer, sans leur précision ni leurs paramètres. Dernier conseil : remplacez vos type char par des varchar, ce sera bien plus lisible.
Ouvrez TOS, nommez puis créez un nouveau projet (sélectionnez-le puis Finish).
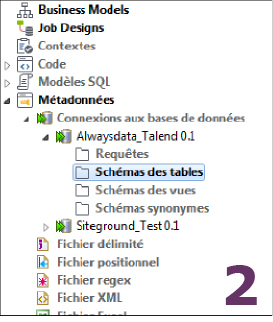
Repérez le panneau Repository dans TOS pour créer des accès aux bases de données (Image 1). Faites un clic-droit sur Métadonnées/Connexion aux bases de données/Créer une connexion, nommez vos deux connexions base1 et base2 (sans espace ni accent) puis Next.
Renseignez ensuite les informations de connexion à la base (Image 1), puis Finish.
 À ce stade vous n'avez fait que créer une possibilité de connexion à un serveur BDD distant (Image 2), ainsi que pré-sélectionner une base de ce serveur (un serveur BDD pouvant bien entendu contenir plusieurs bases de données). Ce n'est qu'une autorisation de connexion que vous conférez à votre projet Talend, mais les tables ou autres objets BDD concernés ne sont pas encore pris en compte par votre projet.
À ce stade vous n'avez fait que créer une possibilité de connexion à un serveur BDD distant (Image 2), ainsi que pré-sélectionner une base de ce serveur (un serveur BDD pouvant bien entendu contenir plusieurs bases de données). Ce n'est qu'une autorisation de connexion que vous conférez à votre projet Talend, mais les tables ou autres objets BDD concernés ne sont pas encore pris en compte par votre projet.
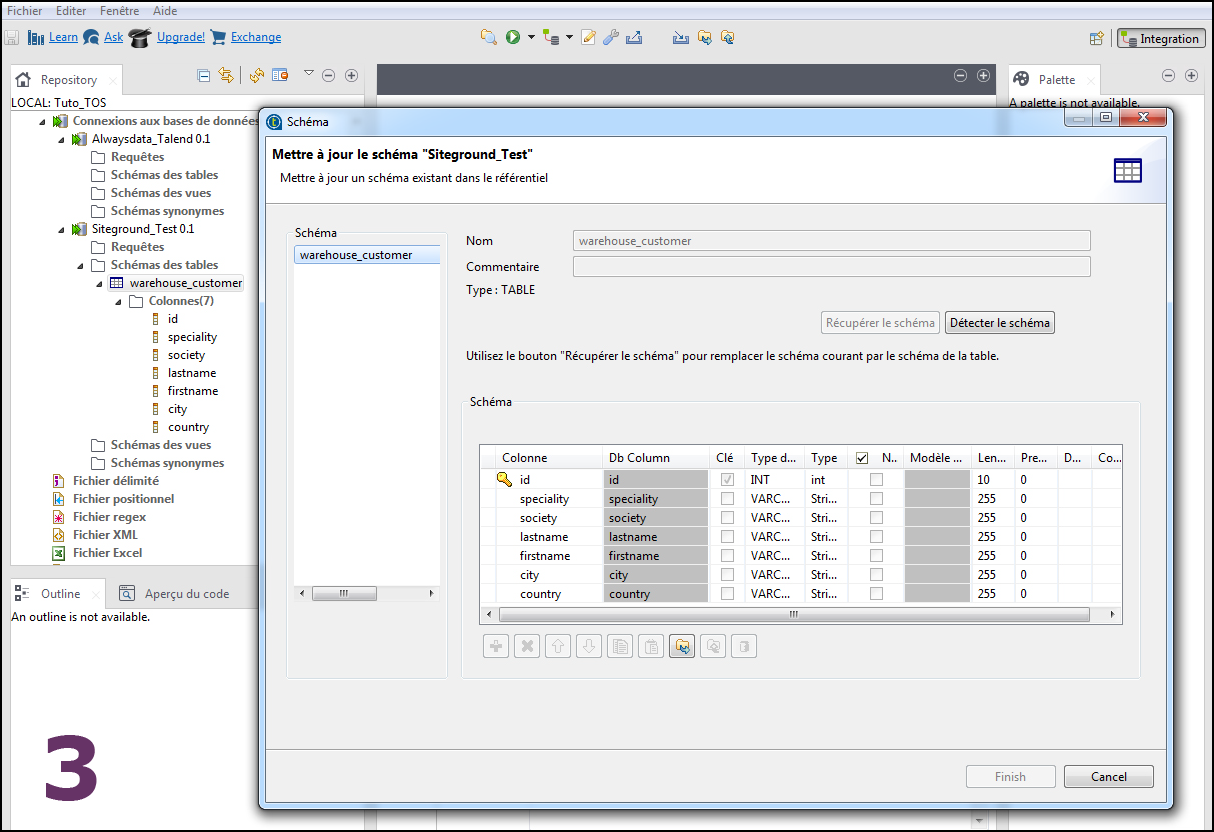
Il vous faut rapatrier les schémas et les objets voulus. Faites un clic-droit sur la connexion (Image 3), option Récupérer le schéma puis Next, afin de récupérer les schémas des objets voulus dans Talend (ce n'est pas les données elles-mêmes, juste leur forme, leur structure).
Sélectionnez les tables souhaitées et attendez de voir Succès en Statut de création (sur la droite).
C'est ensuite le bon moment pour vérifier que Talend récupère correctement la structure de votre table (Image 3). Vérifiez bien les champ de type text et integer par exemple.
Job d'import avec le composant tJavaflex
Cas courant où l'on souhaite agréger des données provenant de plusieurs bases dans un entrepôt, et/ou exécuter un script en dehors du serveur de production.
Vous avez déjà importé les deux fichiers de test customer et warehouse_customer dans deux serveurs différents, tous deux connectés à votre projet Talend. Ces deux tables ont l'exacte même structure.
Considérez la table customer comme la table du serveur de production, et la table warehouse_customer comme l'entrepôt, la base sur laquelle nous souhaitons re-travailler les données, les modifier, les agréger... Imaginez qu'au lieu d'avoir une seule table, nous en ayons plusieurs, avec des jointures à rétablir, des livrables à produire sur demande... Nous serions alors content d'automatiser les imports de données depuis les bases de production jusqu'à l'entrepôt de données.

Composant d'entrée
Créez votre 1er job avec un clic-droit sur Job Designs/Créer un Job (Image 4). Nommez-le Import_vers_warehouse par exemple, puis Finish.
Un job vide a été créé et le Job Designer est ouvert. Nous allons commencer par appeler notre table à importer, soit notre table originale, celle du serveur de production (customer) dans un composant tMysqlInput.
Dans la Palette de droite cherchez le composant tMysqlInput et tirez-le dans le Job Designer (Image 4).
Sélectionnez le composant (il s'affiche alors dans un rectangle de redimensionnement) et allez à l'onglet Composant dans le panneau du bas (image 5). Dans Type de propriété choisissez Référentiel (c'est le référentiel de vos métadonnées).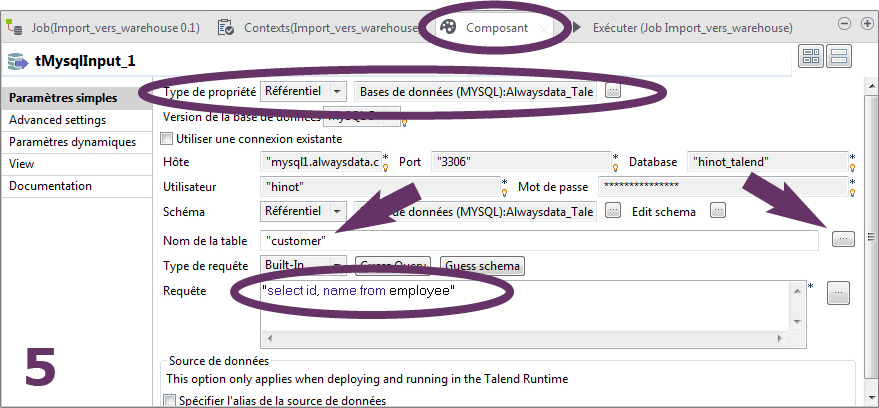
Des champs apparaissent et se pré-remplissent (image 5), mais observez que vous pouvez changer la table pointée (au clavier ou via le bouton sur la droite du champ Nom de la table) et qu'une requête SQL de test est apparue dans le champ Requête. Changez la requête par "select * from customer", puis Guess schema, qui va charger le schéma temporaire de votre réquête.
Astuce
Sur de grosses tables, cette opération de génération du schéma à cette étape du logiciel peut parfois poser problème. Essayez alors de filtrer votre requête (mention des champs à appeler au lieu de *, clause WHERE...) ou simplement d'utiliser le Schéma issu de votre Métadonnées, déja généré (la table de la connexion en question).
Composant de sortie
Faite la même chose avec la table de sortie warehouse_customer dans un nouveau composant tMysqlOutput.
Remarquez que pour ce composant de sortie (output) vous n'avez pas de requête SQL à créer. Il faudra plutôt mapper les champs qui vont recevoir les données (qui elles ont déjà été définies dans la requête SQL du composant d'entrée).
Composant JavaFlex
Nous allons maintenant appeler dans le Designer le composant tJavaFlex (dans la Palette, onglet Code Utilisateur). Tirez-le dans le Designer au coté de vos deux autres composants. Maintenant créez vos relations entre vos trois composants, en tirant du clic-droit le composant d'entrée vers tJavaFlex, puis le composant tJavaFlex vers le composant de sortie (Image 6). Confirmez la récupération du schéma du composant cible.
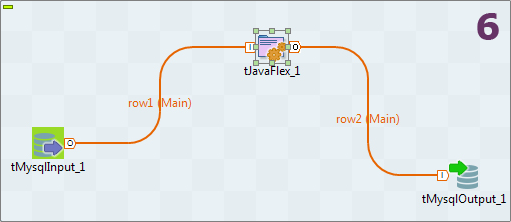 Il vous reste encore à Synchroniser les colonnes depuis le composant tJavaFlex et/ou éditer son schéma, afin de vérifier le mappage des champs ou le mettre à jour.
Il vous reste encore à Synchroniser les colonnes depuis le composant tJavaFlex et/ou éditer son schéma, afin de vérifier le mappage des champs ou le mettre à jour.
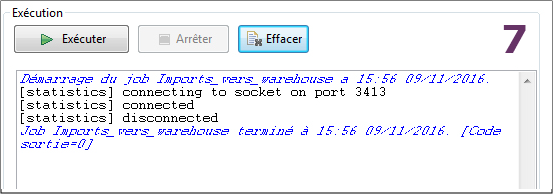
Exécutez le job (onglet Exécuter dans la panneau du bas). Classiquement Talend commitera la BDD en lots de lignes (avec une vitesse par défaut, paramétrable dans les Advanced settings des composants de sortie, mais elle convient très bien ainsi, et dépend en plus des index existants sur vos tables).
Vérifiez vos erreurs ou succès dans le log de sortie (Image 7). Les 1ère lignes en rouge sont souvent les plus instructives (du moins les plus compréhensibles...). Les erreurs les plus courantes dans ce type d'opération concerneront les accès aux Métadonnées (les connexions aux BDD) ou le mappage des champs.
Après confirmation allez vérifier votre table de sortie warehouse_customer, sa structure et ses données.
À ce stade vous pouvez déjà enregistrer votre projet Talend. Notez qu'un projet Talend peut être exporté sous la forme d'une archive, pour exploitation sur une autre machine. L'archive récupèrera la totalité des paramètres de votre projet, y compris les identifiants et mots de passe de connexion à vos métadonnées.
Exercices
-
Essayez maintenant de modifier des lignes de votre table d'origine puis de relancer le job. Que constatez-vous ? Solutionnez le problème en jouant avec les différentes options disponibles dans Talend.
- À partir de l'exemple précédent et des tables customer et warehouse_customer, créez un job qui, sans toucher à la table de production, ramène dynamiquement dans l'entrepôt une concaténation des noms et prénoms.
Exécuter du code SQL dans un job
Souvent on souhaite exécuter du code SQL dans un job, après un import massif par exemple, pour établir des jointures dans des tables ou vues temporaires, faire des corrections de chaînes en vue de besoins métiers, des exports formatés, etc...
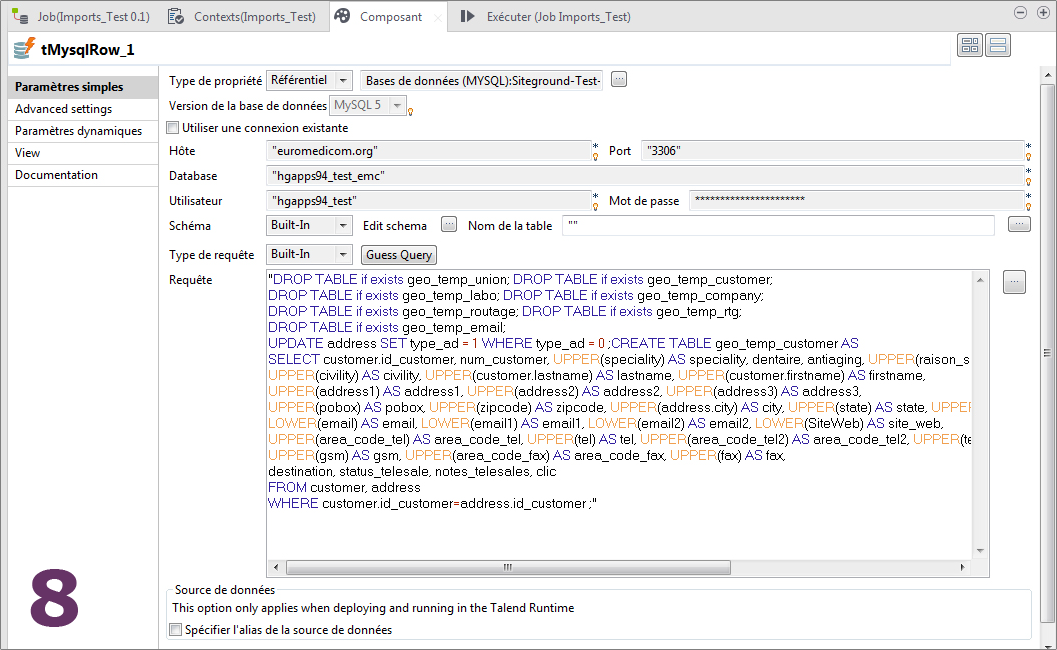
Le composant tMysqlRow (dans l'onglet Bases de données/MySQL de la Palette) est l'un des moyens d'y parvenir.
Sélectionnez le Référentiel à utiliser (la connexion en question, c'est-à-dire la base de données sur laquelle exécuter le code SQL), mais ne choisissez pas de table si vos requêtes tapent dans plusieurs tables.
Astuce
Si votre code SQL contient une succession de requêtes (séparées par ;), alors vous devez autoriser l'exécution de plusieurs requêtes d'affilées dans les Paramètres JDBC supplémentaires des Advanced settings du composant, en ajoutant allowMultiQueries=true à vos paramètres éventuellement déjà existants, séparé du signe &.
Vous pouvez également ajouter ce paramètre directement dans votre Métadonnée.
Exercices
- Que fait la requête CREATE TABLE de l'image 8 ? Pourquoi les autres requêtes en amont sont-elles nécessaires ?
- Créez un champ area qui ramène automatiquement dans l'entrepôt le continent des pays.
- Créez une vue qui compte le nombre de clients par pays par ordre décroissant.
- Ajoutez la suppression des clients dont la company est vide.
Transfert de plusieurs tables MySQL vers Postgres
Importez les fichiers person et address dans une base MySQL.
Importez les tables mes_adresses et mes_personnes dans votre base Postgres locale. Ces dernières tables pour Postgres sont vides.
Créez un nouveau job important les données Mysql vers Postgres. Cette fois vous pouvez tirez vos métadonnées directement dans le designer, ça sera plus rapide mais attention aux choix Input et Ouput ! Utilisez le composant tJavaflex pour ces imports.
Remarquez qu'avec un simple Sync column puis Exécution du job, les erreurs retournées par Talend sont inbuvables. Il s'agit pourtant des mêmes erreurs de traitement de certains champs numériques et/ou clé primaire, mais mal interprêtés quand nous pointons vers Postgres. Modifiez le mappage de votre composant JavaFlex ou vos Actions sur la table, et recommencez.
Jointure dans un job avec le composant tMap
Nous allons maintenant, dans le même job que précédemment (import de Mysql vers Postgres), joindre nos deux tables Postgres mes_personnes et mes_adresses dans une nouvelle table MySQL mes_clients.
Utilisez ici le composant tMap, mais notez qu'en réalité ce composant n'est pas idéal pour faire des jointures complexes. Il est tout indiqué quand vous souhaitez faire une jointure de tables d'une base à une autre base. Mais pour des jointures plus complexes, mieux paramétrables, ramenez d'abord vos tables impliquées dans une seule base (composant tJaveFlex par exemple) puis utilisez un requêtage dans un composant Input, en écrivant votre/vos jointure(s) en pur SQL.
Utilisez le fichier mes_clients pour créer dans MySQL une table vide.
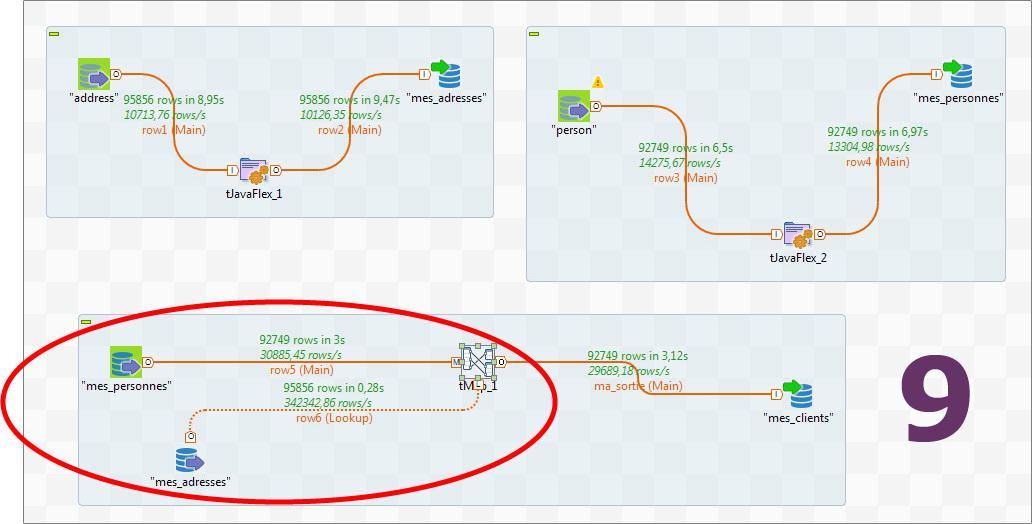
Modifiez ensuite votre job afin d'arriver à un design de ce type (Image 9).
Nommez votre sortie, puis rentrez dans le schéma du composant tMap (Image 10)
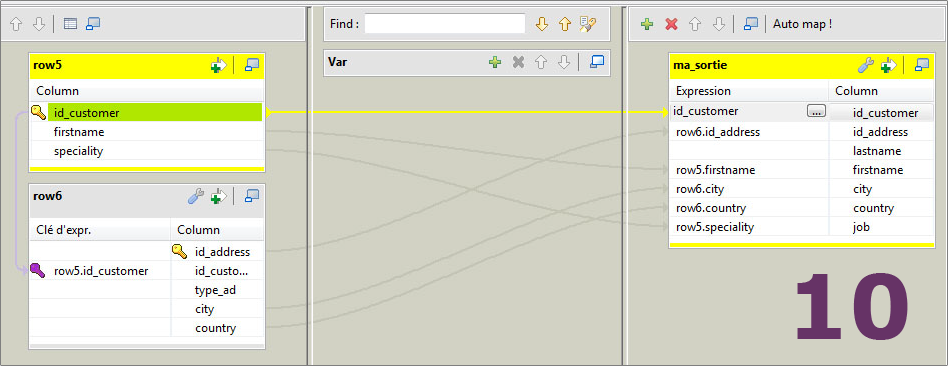
Il ne vous reste qu'à gérer les jointures et destinations (commencez par lier vos tables en entrée), puis à exécuter votre job.
Exercices
Importez le fichier society_coords.sql dans votre base MySQL. Le champ coordinates contient des points géographiques au format Google.
Créez un job qui ramène la table society_coords dans une table Postgres en transformant le champ des coordonnées géographiques en un format utilisable par un SIG (astuce ici).
Quelques liens
Ici un excellent article de Yazid Grim et Fleur-Anne Blain sur developpez.com, non pas au sujet de Talend lui-même, mais sur les ETL en général,le pourquoi, les besoins, les grandes méthodes et erreurs à éviter (2018, et apparemment régulièrement mis à jour).
Éric Quinton (IRSTEA) a diffusé pour le réseau RBDD du CNRS un PDF de présentation de Talend. Ce PDF très clair donne un aperçu concis des fonctionnalités ainsi que quelques repères d'usage (2015).
Article Wikipédia sur les zones de staging, pour mémo.
La documentation Oracle, très fournie, pour info.
| [Table address] | 3833 Ko | |
| [Table SQL des pays du monde] | 21 Ko | |
| [PDF du cours d'Éric Quinton (IRSTEA), diffusé en 2015 grâce au réseau RBDD (CNRS) - Licence CC] | 789 Ko | |
| [Fichier d'import SQL d'une base de contacts humains] | 75 Ko | |
| [Table mes_adresses] | 0.2 Ko | |
| [Table mes_clients] | 0.2 Ko | |
| [Table mes_personnes] | 0.2 Ko | |
| [Table person] | 3050 Ko | |
| [Table society_coords] | 4 Ko | |
| [Fichier d'import SQL d'une base entrepôt vide] | 1 Ko |